
27. März, 2019
Linux Container Basics: Capabilities
Part one of the Linux Container series

Disclaimer: The elaboration associated to this subject results from a Master’s thesis created at SCHUTZWERK in collaboration with Aalen University by Philipp Schmied.
This post of the Linux Container series provides information regarding required fundamentals: Linux capabilities. The following list shows the topics of all scheduled blog posts. It will be updated with the corresponding links once new posts are being released.
- An Introduction to Linux Containers
- Linux Capabilities
- An Introduction to Namespaces
- The Mount Namespace and a Description of a Related Information Leak in Docker
- The PID and Network Namespaces
- The User Namespace
- Namespaces Kernel View and Usage in Containerization
- An Introduction to Control Groups
- The Network and Block I/O Controllers
- The Memory, CPU, Freezer and Device Controllers
- Control Groups Kernel View and Usage in Containerization
The traditional way of handling permissions in Linux involves exactly two process types: Privileged and unprivileged processes. When disregarding capabilities, a process is privileged in case the effective UID is equal to 0 – providing permissions commonly referred to as root privileges. The Linux kernel makes a sharp distinction between privileged and unprivileged processes. For example, privileged processes are allowed to bypass various kernel permission checks [1]. This results in a severe security violation in case untrusted applications are allowed to run with root privileges.
In practice, many system services and applications have to be executed with root privileges. Otherwise the permissions for privileged actions may be missing for a given process. For instance, consider sending ICMP network packets with the ping command: Before capabilities were introduced in the Linux kernel, it was required to execute applications that use raw sockets with elevated privileges – for example using the SUID bit. This theoretically enables the ping process that’s being executed as root to perform privileged system changes or actions that may or may not be desired – additionally to performing the task the process is designated for. Tracing other processes, mounting devices and loading arbitrary kernel modules are some of the actions that will be allowed, additionally to using raw sockets. Therefore, the resulting attack scenario involves executing untrusted binaries or running potentially vulnerable system services with root privileges that may be used by a malicious actor to harm a system.
Because of the security concerns resulting from this, capabilities have been introduced starting from kernel version 2.2. The basic idea is to split the root permission into small pieces that are able to be distributed individually on a thread basis without having to grant all permissions to a specific process at once. A complete list of all available capabilities is present in the capability manual page [1]. In particular, a powerful capability is CAP_SYS_ADMIN which allows to perform comprehensive actions on a system. Please note that this capability is overloaded and its use is discouraged in case better alternatives are available, for example using only a minimal set of capabilities. However, sometimes using this capability is required – for example mount operations require this specific capability. Considering the example with ping would involve adding the CAP_NET_RAW capability to the process making use of raw sockets without having to grant a full set of root privileges.
There are two ways a process can obtain a set of capabilities:
Inherited capabilities: A process can inherit a subset of the parent’s capability set. To inspect the available capabilities for a process, the
/proc/<PID>/statusfile can be examined.File capabilities: It’s possible to assign capabilities to a binary, e.g. using
setcap. The process created when executing a binary of this type is then allowed to use the specified capabilities on runtime. This requires that the process is capability-aware, meaning that it explicitly requests the kernel to allow it to use these capabilities. In case a binary was developed before capabilities were introduced in the kernel, this is not the case as the required system calls for this task were not available at the time the binary was compiled. Hence, the process can fail to perform its designated task because of missing permissions. The Linux kernel manual calls these binaries capability-dumb binaries. A solution for this kind of problem will be discussed later on. Querying a binary for file capabilities is accomplished with thegetcaputility. Performing this on Arch Linux and the includedpingbinary shows that theCAP_NET_RAWfile capability is present, allowing pings without grantingrootpermissions to the process.
The execve System Call
In the Linux kernel, the two main operations regarding processes are fork and exec. The fork system call creates a new process as a copy of the parent process. On the other hand, exec replaces the current process with the contents resulting from executing another program. Both mechanisms are often used in combination, for example when invoking a command in a terminal that’s not a shell-builtin:
forkis called to create a child process.- The child invokes
execto replace its contents with the desired program. - The parent waits for the child to exit and retrieves the exit code.
Please note that fork is required in the scenario above because the original process is not ready to exit yet – it rather invokes an external command and continues its execution afterwards. Without calling fork the current process would be replaced with the desired program. This process exits immediately after its execution which is not desired in the context of a shell.
Discussing exec above does not refer to a single system call. It rather describes the usage of a system call of the exec-family. While there are multiple exec calls, most of them are built by making use of execve. The differences in the function API manifest in the provided parameters for each call.
The execve call is particularly important regarding the various capability sets and thereto related rules which will be discussed further on.
Capability Sets
There exist five different capability sets for each process, each represented by a 64 bit value:
- CapEff: The effective capability set represents all capabilities the process is using at the moment. For file capabilities the effective set is in fact a single bit indicating whether the capabilities of the permitted set will be moved to the effective set upon running a binary. This makes it possible for binaries that are not capability-aware to make use of file capabilities without issuing special system calls.
- CapPrm: The permitted set includes all capabilities a process may use. These capabilities are allowed to be copied to the effective set and used after that.
- CapInh: Using the inherited set all capabilities that are allowed to be inherited from a parent process can be specified. This prevents a process from receiving any capabilities it does not need. This set is preserved across an
execveand is usually set by a process receiving capabilities rather than by a process that’s handing out capabilities to its children. - CapBnd: With the bounding set it’s possible to restrict the capabilities a process may ever receive. Only capabilities that are present in the bounding set will be allowed in the inheritable and permitted sets.
- CapAmb: The ambient capability set applies to all non-SUID binaries without file capabilities. It preserves capabilities when calling
execve. However, not all capabilities in the ambient set may be preserved because they are being dropped in case they are not present in either the inheritable or permitted capability set. This set is preserved acrossexecvecalls.
The sets discussed above allow a fine grained control over how capabilities are being distributed and inherited across processes and binaries. For backwards compatibility all capabilities are being granted to processes running as root user, including SUID binaries.
Capability Rules
Child processes created using fork inherit the full set of the parent’s capabilities. Moreover, there exist rules [1] to determine whether and how capabilities of a process are being inherited or modified upon calling execve when creating a child process:
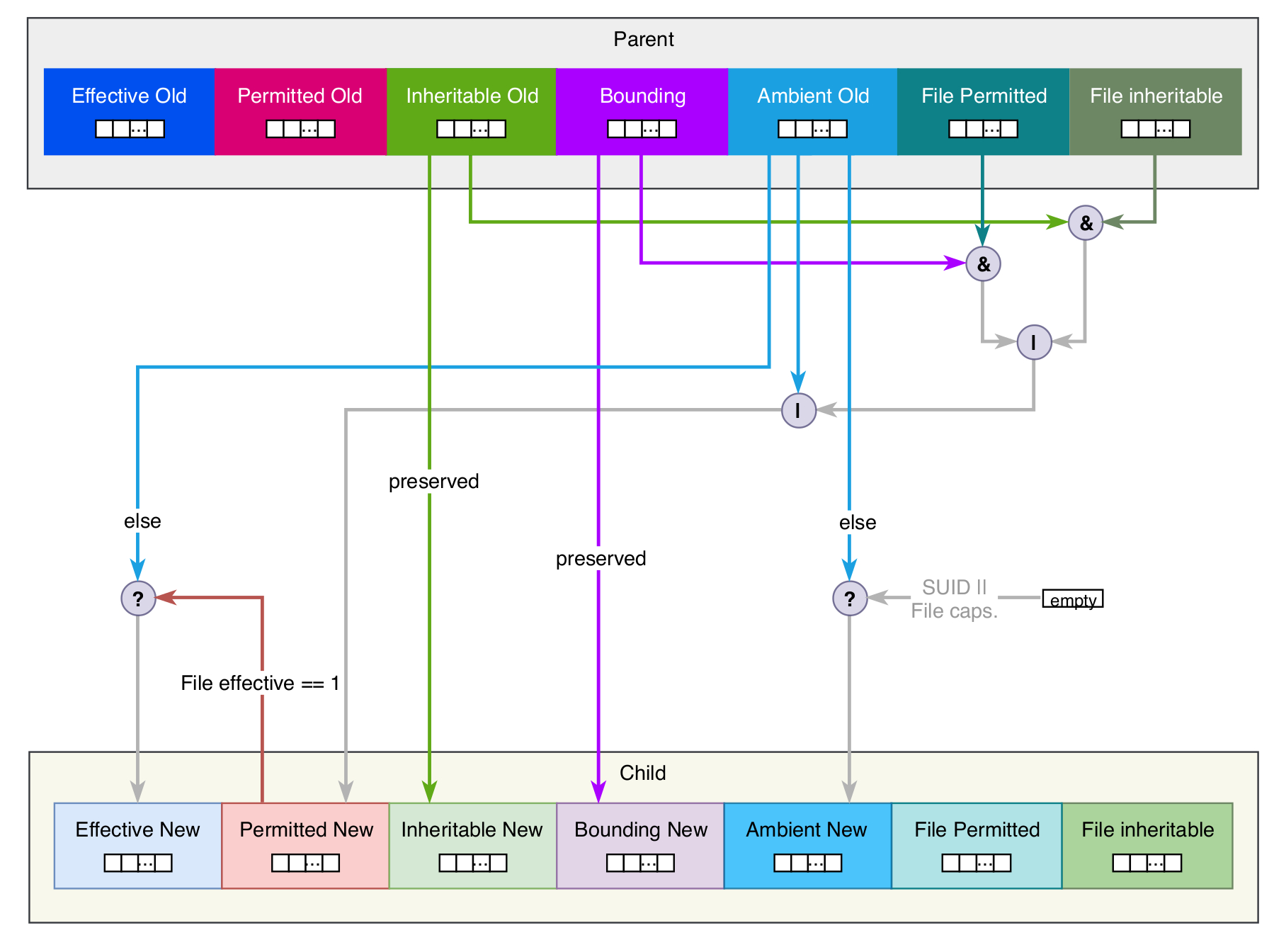
In consequence of the rules above, UID changes have an effect on the available capabilities. If there’s a transition from a zero to a non-zero effective UID value, the effective and permitted capability sets are being cleared.
There may be scenarios where a process requires a capability to perform initial configuration of the system and is then able to drop specific capabilities because their usage is not required anymore. In general it’s a good software design to drop all unnecessary capabilities – container engines like Docker do this by default. To perform this task, the prctl utility can be of use. By utilizing this tool, the secure bits of a process are being manipulated. These flags control how capabilities are being handled for the root user. One flag, namely SECBIT_KEEP_CAPS, controls whether capabilities are being cleared in case a UID transition, for example with setuid, takes place. By setting this bit the current capability set is being retained when switching to another user from a process. For example, the implementation of ntp [2], the NTP daemon drops its capabilities as follows:
- Set the
PR_SET_KEEPCAPSsecure bit usingprctl. At this pointntpdis still being executed withrootprivileges. - Use a
setuidcall to switch to an unprivileged user. Because of the previous step all capabilities are retained across the UID change. - At this point the NTP daemon is running as an unprivileged user. However, all capabilities are still available to the
ntpdprocess. Withcap_set_procof thelibcaplibrary only a selected subset of the currently available capabilities are being explicitly used while all others are being dropped automatically.
Preventing a certain capability from being present in a capability set of a given process can be achieved with the PR_CAPBSET_DROP flag. It effectively drops a capability from the bounding set and drops privileges prior to being added to one of the other capability sets.
While container runtimes can effectively make use of capabilities, the general adoption of this security mechanism that was once the hope for an innovation in privilege management was hindered [3]. This results from capabilities being considered too complex and unhandy to use in the past. After all, specific capability sets and thereto related mechanisms, such as the ambient set that was added in Linux 4.3 (2015), were added long after the initial capability implementation. With the current capability implementation and API many of the original points of criticism can be disqualified.
Next post in series
- Continue reading the next article in this series An Introduction to Namespaces
Follow us on Twitter , LinkedIn , Xing to stay up-to-date